redis拾遗
参考资料:
- redis内存优化:https://cachecloud.github.io/2017/02/16/Redis%E5%86%85%E5%AD%98%E4%BC%98%E5%8C%96/
- Instagram的Redis实践 http://www.cnblogs.com/Laymen/articles/6803485.html
- Efficient Redis Caching Through Hashing
https://sorentwo.com/2015/08/10/efficient-redis-caching-through-hashing.html
实用工具:
- rdb :分析redis内存占用情况
rdb -c memory ./hins3544773_data_20180130032206.rdb –bytes 128 -f ~/work/temp/memory0130.csv
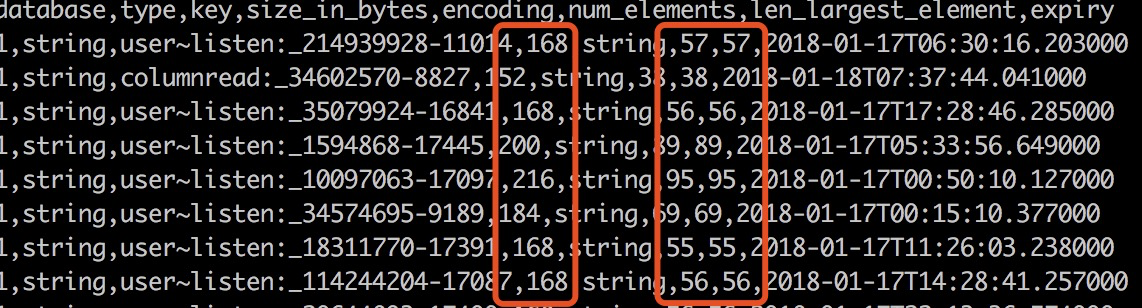
比如首行 168 表示redis 实际分配了的多少内存,后面的57是key value 的大小,可以看到内存利用率并不高 - redis内存分析
redis-memory-for-key -s r-2ze6ae913e05e3f4.redis.rds.aliyuncs.com -a XXX 80179951 - redis-profile 优化建议
redis-profiler -k "user.*" -k "friends.*" -f memoryreport.html /var/redis/6379/dump.rdb
优化点
根据调研,目前redis内存优化,大的方面尽可能的让redis采用压缩方
式存储,比如ziplist/zipmap编码。(ziplist编码需要设置
hash-max-ziplist-entries 、 hash-max-ziplist-value这两个参数,需要重启
redis实例) ziplist 可以压缩内存约6~7倍,但cpu会增加2~3倍,需要做权衡
hash-max-ziplist-value 用来控制hash 的value 最大值,所有的value 都小于
此值时用ziplist大于则退化为hashtable,编码类型转换在Redis写入数据时自动
完成,这个转换过程是不可逆的,转换规则只能从小内存编码向大内存编码转换。
即一旦有一个value 长度大于hash-max-ziplist-value后, 会由ziplist转为
hashtable ,即使这个value 移除后,也不再转化为ziplist
hash使用ziplist的条件满足所有条件: value最大空间(字
节)<=hash-max-ziplist-value field个数<=hash-max-ziplist-entries
由于Hash结构会在单个Hash元素在不足一定数量时进行压缩存储,所以可以
大量节约内存。这一点在上面的String结构里是不存在的。而这个一定数量是由
配置文件中的hash-zipmap-max-entries参数来控制的。经过开发者们的实验,
将hash-zipmap-max-entries设置为1000时,性能比较好,超过1000后HSET命令
就会导致CPU消耗变得非常大。