logstash elasticsearch kibana 日志分析系统 docker 镜像构建
Table of Contents
官方docker 镜像
https://hub.docker.com/_/logstash/
https://hub.docker.com/_/kibana/
https://hub.docker.com/_/elasticsearch/
docker pull logstash docker pull kibana docker pull elasticsearch
demo
sudo docker run -it --name logstash-1 --rm -v "/data/mygame/config/":/config-dir logstash logstash -f /config-dir/logstash_mygame.conf # es kibana 目前在同一个机器上 sudo docker run -d --name es-1 -e ES_HEAP_SIZE=1G -p 9200:9200 -v "/data/mygame/es/logs/":/usr/share/elasticsearch/logs -v "/data/mygame/es/data/":/usr/share/elasticsearch/data elasticsearch -Des.cluster.name="mygame" -De.bootstrap.mlockall=true -Des.node.name="mygame-node-1" sudo docker run --name kibana --link es-1:elasticsearch -p 5601:5601 -d kibana
生成 包含 logstash elasticsearch kibana 的 docker 镜像
网速可以的话,用官方的docker 镜像还是不错的,
直接本目录下
sudo make
或
docker build -t najaplus/logstash:latest .
运行镜像
sudo docker run -t -i najaplus/logstash bash
logstash
logstash 主要功能,收集与解析数据,
从 日志文件或redis 队列中解析出日志数据,经过logstash 一些filter plugin
解析转换为格式化的内容(json) ,存储到某个地方( 可以是redis ,file,elasticseatch),
以便进行数据分析与统计
Elasticsearch
主要功能, 数据的存储与检索,基于json 格式存储,
基于Lucene
- elasticsearch 的几个主要概念
- Cluster 集群
集群有个名字, 防止不同集群间混淆
elasticsearch --cluster.name my_cluster_name --node.name my_node_name
默认名称 elasticsearch
- Node 节点
一个cluster 下分多个node
elasticsearch --cluster.name my_cluster_name --node.name my_node_name
默认名称 elasticsearch
如果只启动一个node 相当于
elasticsearch --cluster.name elasticsearch --node.name elasticsearch
- Index
一些具有共性的documents 的集合,可以认为 一个
index 就是一个类别,比如我把游戏1的信息存到index1上 游戏2的信息存
到index2上index 有名字一个cluster 可以有任意多个index
- Type
Index 下可以定义多个Type
可以认为是编程语言里的struct/class
a type is defined for documents that have a set of common fields.
- Document
docuemnt 存储具体和信息,如果Type 当成java里的Class ,则Document 可以认为是这个Class 的实例
在 elasticsearch中它实际是一个json
- Shards&Replication
架构层面上的东西 ,
可以进行分片,及主从 这个可以参考mysql 的数据库分片 与主从
一个index 内的数据量可能极大,可以将index 分成多片(称为shard)
当定义index 时 ,可以指定将此index 分成n个shards
Each shard is in itself a fully-functional and independent
"index" that can be hosted on any node in the cluster.
可以认为index 与shards是逻辑上的, 而 cluster 与node 上架构上的。
一个index 分为多个shards(s1,s2,s3) ,一个cluster 分为多个node(n1,n2,n3)
将shard s1,s2,s3 分别放到n1,n2,n3节点上
而Replication 可以认为是从库,
存在的意义,
- 备份,及当某个node 挂了 可以failover, 以保证 高可用性(hight available)
查询可以在从库上进行
默认情况下 一个index 有5个shard, 每个shard 有一个 replica shards,即共有10个shards
通常情况下 replica shard 肯定跟primary shard 不在同一个节点上(这样从库还真正有意义)
- 备份,及当某个node 挂了 可以failover, 以保证 高可用性(hight available)
- Cluster 集群
- 启动
elasticsearch 基于Lucene,而Lucene 使用java 编写,所以java jdk 是安装所必须的
elasticsearch 或 elasticsearch --cluster.name my_cluster_name --node.name my_node_name
启动之后9200端口会监听http 请求
- 检查节点状态
curl 'localhost:9200/_cat/health?v'deployer@iZ94badqop7Z logstash_demo/demo1 (master) $ curl 'localhost:9200/_cat/health?v'
epoch timestamp cluster status node.total node.data shards pri relo init unassign pending_tasks max_task_wait_time active_shards_percent
1462637474 00:11:14 elasticsearch yellow 1 1 5 5 0 0 5 0 - 50.0%
- 查看各线程拥堵情况
GET /_cat/thread_pool?v
- 获取node 列表
curl 'localhost:9200/_cat/nodes?v'deployer@iZ94badqop7Z logstash_demo/demo1 $
host ip heap.percent ram.percent load node.role master name
120.24.77.58 120.24.77.58 7 92 0.17 d * zjh
- 查看集群上有哪个index
curl 'localhost:9200/_cat/indices?v'health status index pri rep docs.count docs.deleted store.size pri.store.size
yellow open logstash-2016.05.07 5 1 6 0 17.3kb 17.3kb
可以看到index 的名字, primary个数 ,replica个数 ,docuemnts数量,
- 创建一个index
curl -XPUT 'localhost:9200/customer?pretty'{
"acknowledged" : true
}
#指定 shard 与replicas 数量 curl -XPUT 'http://localhost:9200/twitter/' -d '{ "settings" : { "index" : { "number_of_shards" : 3, "number_of_replicas" : 2 } } }'
- 删除某个index
curl -XDELETE 'localhost:9200/customer?pretty' - 创建某个Type 的Documents
这里在index:customer上创建了一个type 为 external id=1的document
如果id=1的已经存在,则会替换之
curl -XPUT 'localhost:9200/customer/external/1?pretty' -d ' { "name": "John Doe" }'
{
"_index" : "customer",
"_type" : "external",
"_id" : "1",
"_version" : 1,
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"created" : true
}
实际情况上 ,在创建document 时, 不必手动去创建相应的index,执行上述命令, 如果没有index:customer,则会自动创建
curl -XPUT 'localhost:9200/custome2r/external/1?pretty' -d '
{
"name": "John Doe"
}'
- 查询某个document
curl -XGET 'localhost:9200/customer/external/1?pretty'{
"_index" : "customer",
"_type" : "external",
"_id" : "1",
"_version" : 1,
"found" : true,
"_source" : {
"name" : "John Doe"
}
}
- update document
update 实际是先删除后增加
curl -XPOST 'localhost:9200/customer/external/1/_update?pretty' -d ' { "doc": { "name": "Jane Doe","age":11 } }'
通过script 修改age 的值 +5
script 文档 https://www.elastic.co/guide/en/elasticsearch/reference/current/modules-scripting.html
curl -XPOST 'localhost:9200/customer/external/1/_update?pretty' -d ' { "script" : "ctx._source.age += 5" }'
目前的版本,script 操作只能会对一个docuemnt ,以后或许会支持类似于sql update 的操作 ,同时修改多个
- delete document
curl -XDELETE 'localhost:9200/customer/external/2?pretty' - 批量操作
同时创建id=1,2的 type:external
curl -XPOST 'localhost:9200/customer/external/_bulk?pretty' -d ' {"index":{"_id":"1"}} {"name": "John Doe" } {"index":{"_id":"2"}} {"name": "Jane Doe" } '
修改一个, 同时删除另一个
curl -XPOST 'localhost:9200/customer/external/_bulk?pretty' -d ' {"update":{"_id":"1"}} {"doc": { "name": "John Doe becomes Jane Doe" } } {"delete":{"_id":"2"}} '
- 批量从文件导入
假如有文件 account.json
{"index":{"_id":"1"}} {"account_number":1,"balance":39225,"firstname":"Amber","lastname":"Duke","age":32,"gender":"M","address":"880 Holmes Lane","employer":"Pyrami","email":"amberduke@pyrami.com","city":"Brogan","state":"IL"} {"index":{"_id":"6"}} {"account_number":6,"balance":5686,"firstname":"Hattie","lastname":"Bond","age":36,"gender":"M","address":"671 Bristol Street","employer":"Netagy","email":"hattiebond@netagy.com","city":"Dante","state":"TN"} {"index":{"_id":"13"}} {"account_number":13,"balance":32838,"firstname":"Nanette","lastname":"Bates","age":28,"gender":"F","address":"789 Madison Street","employer":"Quility","email":"nanettebates@quility.com","city":"Nogal","state":"VA"} {"index":{"_id":"18"}} {"account_number":18,"balance":4180,"firstname":"Dale","lastname":"Adams","age":33,"gender":"M","address":"467 Hutchinson Court","employer":"Boink","email":"daleadams@boink.com","city":"Orick","state":"MD"} {"index":{"_id":"20"}} {"account_number":20,"balance":16418,"firstname":"Elinor","lastname":"Ratliff","age":36,"gender":"M","address":"282 Kings Place","employer":"Scentric","email":"elinorratliff@scentric.com","city":"Ribera","state":"WA"}curl -XPOST 'localhost:9200/bank/account/_bulk?pretty' --data-binary "@account.json"
curl 'localhost:9200/_cat/indices?vcurl 'localhost:9200/_cat/indices?v' health index pri rep docs.count docs.deleted store.size pri.store.size yellow bank 5 1 1000 0 424.4kb 424.4kb
- 批量从文件导入
- 查看mapping
mapping 主要功能是用来指定 field 的类型的,
默认在创建document 时, 有dynamic mapping 机制 自动指定field 类型等,
比如上面创建 customer/external 时
#查看index=customer ,type=external 对应的 mapping # 可以看到,它有一个field:name 对应类型为string curl -XGET 'http://localhost:9200/customer/_mapping/external?pretty' { "customer" : { "mappings" : { "external" : { "properties" : { "name" : { "type" : "string" } } } } } }
#查看所有index 的mappin
curl -XGET 'http://localhost:9200/_mapping?pretty' 或 curl -XGET 'http://localhost:9200/_all/_mapping?pretty'
查看某两个index 的mapping
curl -XGET 'http://localhost:9200/_mapping/twitter,kimchy' 或 curl -XGET 'http://localhost:9200/_all/_mapping/tweet,book'
- put mapping
put mapping ,可以实现
- 创建index 时 指定mapping
curl -XPOST localhost:9200/test -d '{ "settings" : { "number_of_shards" : 1 }, "mappings" : { "type1" : { "properties" : { "field1" : { "type" : "string", "index" : "not_analyzed" } } } } }'
- 向一个已经存在的index 加一个新的type (index 似乎必须存在)
curl -XPUT 'http://localhost:9200/gold' -d ' {"mappings":{ "gold_change":{ "properties":{ "uin":{ "type":"string", "index":"not_analyzed" }, "change":{ "type":"long" }, "timestamp":{ "type":"date", "format" : "strict_date_optional_time||epoch_millis" } } } }} ' #注上面 "index":"not_analyzed" 说明 不对uin 进行分词(把uin 对应的内容当成一个完整的term) ,可接受的类型"no","analyzed" #no 表示, 此字段不可查询 analyzed 表示会进行分词 # 更多参数 ,见 #https://www.elastic.co/guide/en/elasticsearch/reference/current//mapping-index.html
- 向一个已经存在的type 加一个新的field
curl -XPUT 'http://localhost:9200/gold/_mapping/gold_change' -d ' { "properties": { "name": { "type": "string" } } }'
不能实现的功能,
如果一个type 已经存的某field ,则不能修改在field 的类型。
要想修改 只能在 未创建任何document 之前 put mapping
通常情况下, 如果未手动put mapping
在创建第一个document 时, 会自动创建相应的mapping
但是此时 ,mapping 里出现的field 类型后期不能进行修改了。
如果自动创建的mapping 不能满足你的需求。 则要提前创建。
比如, 本可能是时间的字段, 默认可能会是long
实际是个long , 本默认是string
- 创建index 时 指定mapping
- mapping types
string, date, long, double, boolean or ip
object, nested 等json 或对象 等特殊类型
geo_point, geo_shape, or completion等表示地图信息的类型
date 需要指定format
"timestamp":{ "type":"date", "format" : "strict_date_optional_time||epoch_millis" } // 或 #"format": "yyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"
https://www.elastic.co/guide/en/elasticsearch/reference/current//mapping.html#mapping-type
需要特别说明的一点是 。
同一个index 下 , 相同名字的field ,不类在哪个type 中, 必须保证 此field 的类型 处处相同
即 ,title 字段可能出现在user 可能出现在group 中 , 不论在哪里 title 必须都是string 或别的类型
- Index Template
template 存在的意义是,比如logstash 在创建index 可能是根据日期
创建不同的index ,以避免某个index 数据量过大,
如 每月建一个index,
为了保证这些每月自动创建的index 对其mapping,setting 进行定制,
保证其属性一致。 从而出现了template
template 需要一个index pattern,来匹配决定 新创建的index 是否需要应用此模版
# 只要新创建的index 前缀是"gold-*" ,就会应用此 template curl -XPUT 'http://localhost:9200/_template/gold_template' -d ' { "template": "gold-*", "settings": { "number_of_shards": 1 }, "mappings": { "gold_change": { "_source": { "enabled": false }, "properties": { "host_name": { "type": "string", "index": "not_analyzed" }, "created_at": { "type": "date", "format": "EEE MMM dd HH:mm:ss Z YYYY" } } } } } '
- Search
- 查所有
# 两种方式, 一种通过参数 ,一种通过request body 发送json内容 curl 'localhost:9200/bank/_search?q=*&pretty' #或 curl -XPOST 'localhost:9200/bank/_search?pretty' -d ' { "query": { "match_all": {} } }'
{ "took" : 63, "timed_out" : false, "_shards" : { "total" : 5, "successful" : 5, "failed" : 0 }, "hits" : { "total" : 1000, "max_score" : 1.0, "hits" : [ { "_index" : "bank", "_type" : "account", "_id" : "1", "_score" : 1.0, "_source" : {"account_number":1,"balance":39225,"firstname":"Amber","lastname":"Duke","age":32,"gender":"M","address":"880 Holmes Lane","employer":"Pyrami","email":"amberduke@pyrami.com","city":"Brogan","state":"IL"} }, { "_index" : "bank", "_type" : "account", "_id" : "6", "_score" : 1.0, "_source" : {"account_number":6,"balance":5686,"firstname":"Hattie","lastname":"Bond","age":36,"gender":"M","address":"671 Bristol Street","employer":"Netagy","email":"hattiebond@netagy.com","city":"Dante","state":"TN"} } ... ]}} - 查询语法
https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl.html
查询语法,包含两个Context: Query Context和Filter Context
Filter 用来 过滤document 是否包含在结果集中,主要用于过滤掉不符合的document
而Query context 是搜索引擎层面的,用来计算给定的关键词与document 的匹配度
它会计算一个score ,来标定这个这键字与document的匹配度。当然它也会过滤掉一些不匹配的document
而filter 是不计算score的 。
可以认为 filter context ,是严格过滤的, 即, 通常条件类似
status==1
age>0
age<10
name=="age"
而 query context ,是基于字符匹配层面的"匹配"(搜索引擎)
比如
curl -XPOST 'localhost:9200/bank/_search?pretty' -d ' { "query": { "bool": { "must": [ { "match": { "title": "Search" }}, { "match": { "content": "Elasticsearch" }} ], "filter": [ { "term": { "status": "published" }}, { "range": { "publish_date": { "gte": "2015-01-01" }}} ] } } }
filter:中 指定
- status必须== "published"
- publish_date > 2015-01-01
query 中 bool must,match 则是query context的
意即,使用bool 这类的must 子句来query ,(must 可以理解为 and or not 中的and)
而两个match ,则是要匹配的条件,
即title 中含"search",content中含 "Elasticsearch"
- size 指定返回多少个结果
curl -XPOST 'localhost:9200/bank/_search?pretty' -d ' { "query": { "match_all": {} }, "size": 1 }'
- from and sort 返回结果集的 第3,4,5条
from 控制从哪条记录起始(0based)
sort:使用balance 降序排列
curl -XPOST 'localhost:9200/bank/_search?pretty' -d ' { "query": { "match_all": {} }, "from":2, "size": 3, "sort": { "balance": { "order": "desc" } } }'
- 只返回特定的字段 _source
curl -XPOST 'localhost:9200/bank/_search?pretty' -d ' { "query": { "match_all": {} }, "from":2, "size": 3, "sort": { "balance": { "order": "desc" } }, "_source":["account_number","balance"] }'
{ "took" : 10, "errors" : true, "timed_out" : false, "_shards" : { "total" : 5, "successful" : 5, "failed" : 0 }, "hits" : { "total" : 8, "max_score" : null, "hits" : [ { "_index" : "bank", "_type" : "account", "_id" : "1", "_score" : null, "_source" : { "account_number" : 1, "balance" : 39225 }, "sort" : [ 39225 ] }, { "_index" : "bank", "_type" : "account", "_id" : "13", "_score" : null, "_source" : { "account_number" : 13, "balance" : 32838 }, "sort" : [ 32838 ] }, { "_index" : "bank", "_type" : "account", "_id" : "37", "_score" : null, "_source" : { "account_number" : 37, "balance" : 18612 }, "sort" : [ 18612 ] } ] } } - Full Text Query (全文搜索) "match" "multi_match" 匹配级别的
https://www.elastic.co/guide/en/elasticsearch/reference/current//full-text-queries.html
查 account_number=37的
curl -XPOST 'localhost:9200/bank/_search?pretty' -d ' { "query": { "match":{"account_number":37} }, "_source":["account_number","balance"] }'
match_phrase似乎跟match 是一样的(返回结果好像是一样的)
词组级别的查询
curl -XPOST 'localhost:9200/bank/_search?pretty' -d ' { "query": { "match_phrase":{"account_number":37} }, "_source":["account_number","balance"] }'
{ "took" : 33, "timed_out" : false, "_shards" : { "total" : 5, "successful" : 5, "failed" : 0 }, "hits" : { "total" : 1, "max_score" : 0.30685282, "hits" : [ { "_index" : "bank", "_type" : "account", "_id" : "37", "_score" : 0.30685282, "_source" : { "account_number" : 37, "balance" : 18612 } } ] } }- 根据字段查询选定条件的 (term 级别)
term, terms,range, exists,missing,prefix,wildcard ,regex,,type
term 可以认为 那个字段 严格==查询的内容
curl -XPOST 'localhost:9200/zjh_login*/_search?pretty' -d ' { "query": { "term":{ "text":"hello world" } } }' 假如text字段的mapping ,指定text 进行分词, 假如有个document.text="hello world", 则匹配失败, 因为text 被分词成了"hello" 和"world" "hello world"!="hello" "hello world"!="world" 所以不匹配
- 根据字段查询选定条件的 (term 级别)
- bool 语法(must,must_not,should)
相当于 and not or
查 gender==M and age==32
curl -XPOST 'localhost:9200/bank/_search?pretty' -d ' { "query": { "bool": { "must": [ { "match": { "gender": "M" } }, { "match": { "age": "32" } } ] } } }'
查 age==31 or age==32
curl -XPOST 'localhost:9200/bank/_search?pretty' -d ' { "query": { "bool": { "should": [ { "match": { "age": "31" } }, { "match": { "age": "32" } } ] } } }'
查 (gender=M and age==32) and( balance!= 32838 and balance!= 18612 )
curl -XPOST 'localhost:9200/bank/_search?pretty' -d ' { "query": { "bool": { "must": [ { "match": { "gender": "M" } }, { "match": { "age": "32" } } ], "must_not": [ { "match": { "balance" : 32838} }, { "match": { "balance" : 18612} } ] } } }'
- filter 结果集的过滤
curl -XPOST 'localhost:9200/bank/_search?pretty' -d ' { "query": { "bool": { "must": [{ "match": { "gender": "M" } }], "filter": {"range":{ "balance":{"gte":10,"lte":20000}}} } } }'
- Aggregations(合计) ==sql group by
curl -XPOST 'localhost:9200/bank/_search?pretty' -d ' { "size": 0, "aggs": { "group_by_state_just_a_name": { "terms":{"field":"state"} } } }'
这里terms 是按field:state 进行统计其数量, 以计 {state:"mystate",count:100} 的形式返回
size=0 意思是说只返回 统计结果 即下面的 aggregations里的数据,而hits 结果为空
SELECT state, COUNT(*) FROM bank GROUP BY state ORDER BY COUNT(*) DESC
{ "took" : 5, "timed_out" : false, "_shards" : { "total" : 5, "successful" : 5, "failed" : 0 }, "hits" : { "total" : 8, "max_score" : 0.0, "hits" : [ ] }, "aggregations" : { "group_by_state" : { "doc_count_error_upper_bound" : 0, "sum_other_doc_count" : 0, "buckets" : [ { "key" : "il", "doc_count" : 1 }, { "key" : "in", "doc_count" : 1 }, { "key" : "md", "doc_count" : 1 }, { "key" : "ok", "doc_count" : 1 }, { "key" : "pa", "doc_count" : 1 }, { "key" : "tn", "doc_count" : 1 }, { "key" : "va", "doc_count" : 1 }, { "key" : "wa", "doc_count" : 1 } ] } } }curl -XPOST 'localhost:9200/bank/_search?pretty' -d ' { "size": 0, "aggs": { "group_by_state": { "terms": { "field": "state", "order": { "average_balance": "desc" } }, "aggs": { "average_balance": { "avg": { "field": "balance" } } } } } }'
{ "took" : 5, "timed_out" : false, "_shards" : { "total" : 5, "successful" : 5, "failed" : 0 }, "hits" : { "total" : 8, "max_score" : 0.0, "hits" : [ ] }, "aggregations" : { "group_by_state" : { "doc_count_error_upper_bound" : 0, "sum_other_doc_count" : 0, "buckets" : [ { "key" : "il", "doc_count" : 1, "average_balance" : { "value" : 39225.0 } }, { "key" : "in", "doc_count" : 1, "average_balance" : { "value" : 48086.0 } }, { "key" : "md", "doc_count" : 1, "average_balance" : { "value" : 4180.0 } }, { "key" : "ok", "doc_count" : 1, "average_balance" : { "value" : 18612.0 } }, { "key" : "pa", "doc_count" : 1, "average_balance" : { "value" : 40540.0 } }, { "key" : "tn", "doc_count" : 1, "average_balance" : { "value" : 5686.0 } }, { "key" : "va", "doc_count" : 1, "average_balance" : { "value" : 32838.0 } }, { "key" : "wa", "doc_count" : 1, "average_balance" : { "value" : 16418.0 } } ] } } }curl -XPOST 'localhost:9200/bank/_search?pretty' -d ' { "size": 0, "aggs": { "group_by_age": { "range": { "field": "age", "ranges": [ { "from": 20, "to": 30 }, { "from": 30, "to": 40 }, { "from": 40, "to": 50 } ] } } } }'
curl -XPOST 'localhost:9200/bank/_search?pretty' -d ' { "size": 0, "aggs": { "group_by_age": { "range": { "field": "age", "ranges": [ { "from": 20, "to": 30 }, { "from": 30, "to": 40 }, { "from": 40, "to": 50 } ] } } } }'
- status必须== "published"
- 查所有
- elasticsearch 启动参数
配置 elasticsearch 的JVM 参数
nil
两个环境变量, 尽量不要修改JAVA_OPTS,保持原样, 而修改 ES_JAVA_OPTS
ES_HEAP_SIZE 设置 heap 大小(min =max=this)
ES_MIN_MEM ES_MAX_MEM (分别设置min max )官方不推荐
提前设置好 max-open-files
ulimit -n 查看
Virtual memoryedit
Elasticsearch uses a hybrid mmapfs / niofs directory by default to
store its indices. The default operating system limits on mmap
counts is likely to be too low, which may result in out of memory
exceptions. On Linux, you can increase the limits by running the
following command as root:
sysctl -w vm.max_map_count=262144
To set this value permanently, update the vm.max_map_count setting
in /etc/sysctl.conf.
If you installed Elasticsearch using a package (.deb, .rpm) this
setting will be changed automatically. To verify, run sysctl
vm.max_map_count.
- 配置
/etc/elasticsearch/elasticsearch.yml
有些参数也可以在配置文件中配置
node.name: zjh
cluster.name: my-application
path.data: /data/zjh/es/data
path.logs: /data/zjh/es/log
network.host: 0.0.0.0
http.port: 9200
indices.memory.index_buffer_size: 30%
thread_pool:
write:
size: 32
queue_size: 4000
-Xms31g
-Xmx31g
-XX:+UseG1GC
-XX:MaxGCPauseMillis=200
-XX:+AlwaysPreTouch
-Xss1m
-Djava.awt.headless=true
-Dfile.encoding=UTF-8
-Djna.nosys=true
-XX:-OmitStackTraceInFastThrow
-Dio.netty.noUnsafe=true
-Dio.netty.noKeySetOptimization=true
-Dio.netty.recycler.maxCapacityPerThread=0
-Dlog4j.shutdownHookEnabled=false
-Dlog4j2.disable.jmx=true
-Djava.io.tmpdir=${ES_TMPDIR}
-XX:+HeapDumpOnOutOfMemoryError
-XX:HeapDumpPath=data
-XX:ErrorFile=logs/hs_err_pid%p.log
8:-XX:+PrintGCDetails
8:-XX:+PrintGCDateStamps
8:-XX:+PrintTenuringDistribution
8:-XX:+PrintGCApplicationStoppedTime
8:-Xloggc:logs/gc.log
8:-XX:+UseGCLogFileRotation
8:-XX:NumberOfGCLogFiles=32
8:-XX:GCLogFileSize=64m
9-:-Xlog:gc*,gc+age=trace,safepoint:file=logs/gc.log:utctime,pid,tags:filecount=32,filesize=64m
9-:-Djava.locale.providers=COMPAT
https://www.elastic.co/guide/en/elasticsearch/reference/current/setup-service.html
centos7 上 配置成service
一些配置 在这两个文件里
/usr/lib/systemd/system/elasticsearch.service
/usr/lib/sysctl.d/elasticsearch.conf
kibana
数据的可视化, 主要功能 从 elasticsearch 中查询数据, 将数据以图表的形式展示
kibana 加认证功能。
默认情况下kibana 没有任何认证,如果需要放到外网访问, 很不安全。
elasticsearch 官网有个插件 shield 可以实现认证及权限控制等功能。
但是需要付费,
目前我只需要一个简单认证就可以。
可以使用nginx来挡。
可以参考 http://jixiuf.github.io/blog/nginx%E6%8B%BE%E9%81%97/
kibana 的一些查询
搜索框里可以
reason:"test" # 查reason ="test"
age:[3 20] # range 查询
可也以直接输入 elasticsearch 的json 查询语法
kibana 的可视化 是在上述查询出来的数据上 进行 统计
demo
比如 我打印这样的日志 记录游戏资产变化(金币、钻石等通过key来区分)
2016-05-10_17:43:29 {"logtype":"assets_change","uin":"144150668431540282","key":6,"before":8,"after":4,"change":-4,"reason":"assets_sell_consume","timestamp":1462873382304931}
2016-05-10_17:43:29 {"logtype":"assets_change","uin":"144150668431540282","key":1,"before":19729900,"after":19769900,"change":40000,"reason":"assets_sell_obtain","timestamp":1462873382304931}
根据这样的记录我可以以图表的形式分析资产变化的原因,每天资产是增是减
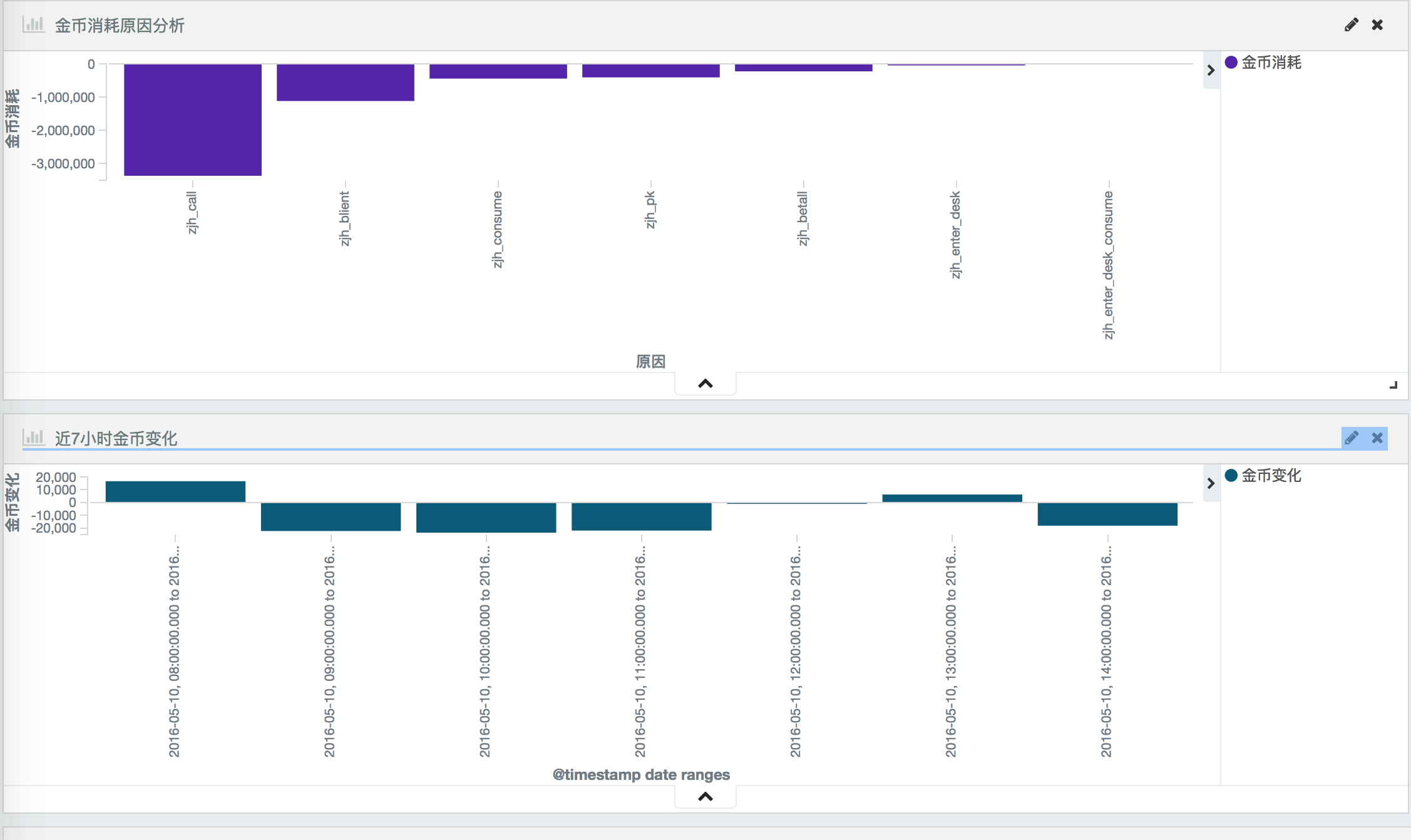
kibana 的迁移
你在kibana 界面里做的配置及 创建的查询 视图都保存在
elasticsearch 内一个 叫 .kibana 的index 下
所以 当你在别的机器上想得到相同配置 相同视图的kibana
就得把 elasticsearch 的.kibana 节点复制到你的新机器上
这里重点说下怎么把kibana4的配置导出并迁移。 如果你不偷懒,可以自己
用pyhton写个elasticsearch的导出程序,实现起来很简单….. 如果你跟我
一样很偷懒,那么就直接用现成的工具。 elasticdump是个node.js开发的一
个小而精的elasticsearch导出程序。
sudo yum install npm npm install -g elasticdump
导出,也可以用来做elasticsearch的备份,elasticdump可以选择性的导出data和mapping。
#具体配置信息 elasticdump --ignore-errors=true --scrollTime=120m --bulk=true --input=http://ip1:9200/.kibana --output=data.json --type=data #导出mapping信息 elasticdump --ignore-errors=true --scrollTime=120m --bulk=true --input=http://ip1:9200/.kibana --output=mapping.json --type=mapping
咱们再把刚才备份的数据,导入到目标elasticsearch上
#导入mapping elasticdump --input=mapping.json --output=http://ip2:9200/.kibana --type=mapping #导入具体的kibana配置信息 elasticdump --input=data.json --output=http://ip2:9200/.kibana --type=data