linux拾遗
Table of Contents
- 几个工具
- IOSTAT 介绍
- VMSTAT 介绍
- 几个性能相关工具
- free 命令详解
- 使某一目录下创建的所有文件目录的groupname 都是 当前用户所属的组
- umask
- setfacl
- mbr and dd
- ctags
- nmap
- tcpdump
- mac shutdown
- linux下分辨率调整
- 通过ssh 连接远程机器上的mysql 等
- iptables 作端口转发
- ssh socat
- ssh tunnel
- tsocks 配置
- adb shell
- curl demo
- time sync
- sed 一些用法
- grep
- find
- “.”点号替代单个字符
- shell for if example
- 用python 格式化json
- awk 怎么去除如果第一列相同,则只取一行?
- awk 替换
- awk 在指定的行添加内容添加行
- 压测用工具
- ab http压测
- tcpcopy 线上数据导入测度服进行压测
- 使用charles在移动设备上捕获https数据包
- 如何应对三高
- ssh 避免输入密码的办法
几个工具
- nload 查看网卡流量
- nethogs iptrafr iftop 查看具体的进程发包收包情况
sudo yum install nethogs - rkhunter linux 安全工具,扫描后门程序(需要刚装机时建立样本进行对比)
rkhunter –propupd 刚装完机 用此命令建立样本
rkhunter -c check
rkhunter –-update 更新数据库, - lsof -i:8888 查看兼听8888端口的程序
- top 按M按内存排序
- tmux
- nc -u localhost 7777 nc 可以跟telnet 一样, 不过支持udp telnet
- 创建虚拟ftp 用户 ftpasswd –passwd –file=/etc/ftpd.passwd –name=ftp –home=/home/ftp –shell=/bin/false –uid 508
exit code $? echo $?
[ $? -eq 0 ] || exit $?; # exit for none-zero return code
# this will trap any errors or commands with non-zero exit status # by calling function catch_errors() trap catch_errors ERR; # # ... the rest of the script goes here # function catch_errors() { # do whatever on errors # # echo "script aborted, because of errors"; exit $?; } find /asda echo "oo"
- strace -p 29064 >/tmp/strace.log 2>&1
cat strace.log|cut -f 1 -d "("|sort|uniq -c
统计某进程系统调用的信息 ,比如归个系统调用多
- tmux attach
C-bd 退出
C-b0 C-b1 C-b2 切tag
C-bs list sessions
C-bn C-bp next prev
C-bc 新建tag
IOSTAT 介绍
Iostat(Input Output statistics)反映了磁盘I/O情况和CPU 活动。
基本语法: iostat <options> interval count
option - 让你指定所需信息的设备,像磁盘、cpu或者终端(-d , -c , -t or
-tdc ) 。x 选项给出了完整的统计结果。iostat的默认参数是tdc(terminal,
disk, and CPU)。如果任何其他的选项被指定,这个默认参数将被完全替代。
-k 以kb的形式显示
如 iostat -d -k -x 1 10
interval – 统计运行的间隔时间(秒),
count – 统计运行的次数
参数说明:
rrqm/s: 每秒进行 merge 的读操作数目。
wrqm/s: 每秒进行 merge 的写操作数目。
r/s: 每秒完成的读 I/O 设备次数。
w/s: 每秒完成的写 I/O 设备次数。
rsec/s: 每秒读扇区数。即 delta(rsect)/s
wsec/s: 每秒写扇区数。即 delta(wsect)/s
rkB/s: 每秒读K字节数。是 rsect/s 的一半,因为每扇区大小为512字节。
wkB/s: 每秒写K字节数。是 wsect/s 的一半。
avgrq-sz: 平均每次设备I/O操作的数据大小 (扇区)。
avgqu-sz: 平均I/O队列长度。即 delta(aveq)/s/1000 (因为aveq的单位为毫秒)。
await: 平均每次设备I/O操作的等待时间 (毫秒)。
svctm: 平均每次设备I/O操作的服务时间 (毫秒)。
%util: 一秒中有百分之多少的时间用于 I/O 操作,或者说一秒中有多少时间 I/O 队列是非空的。
比如当发现util 比较高时, 我们知道io操作比较频繁
iostat -d -k -x 1 100
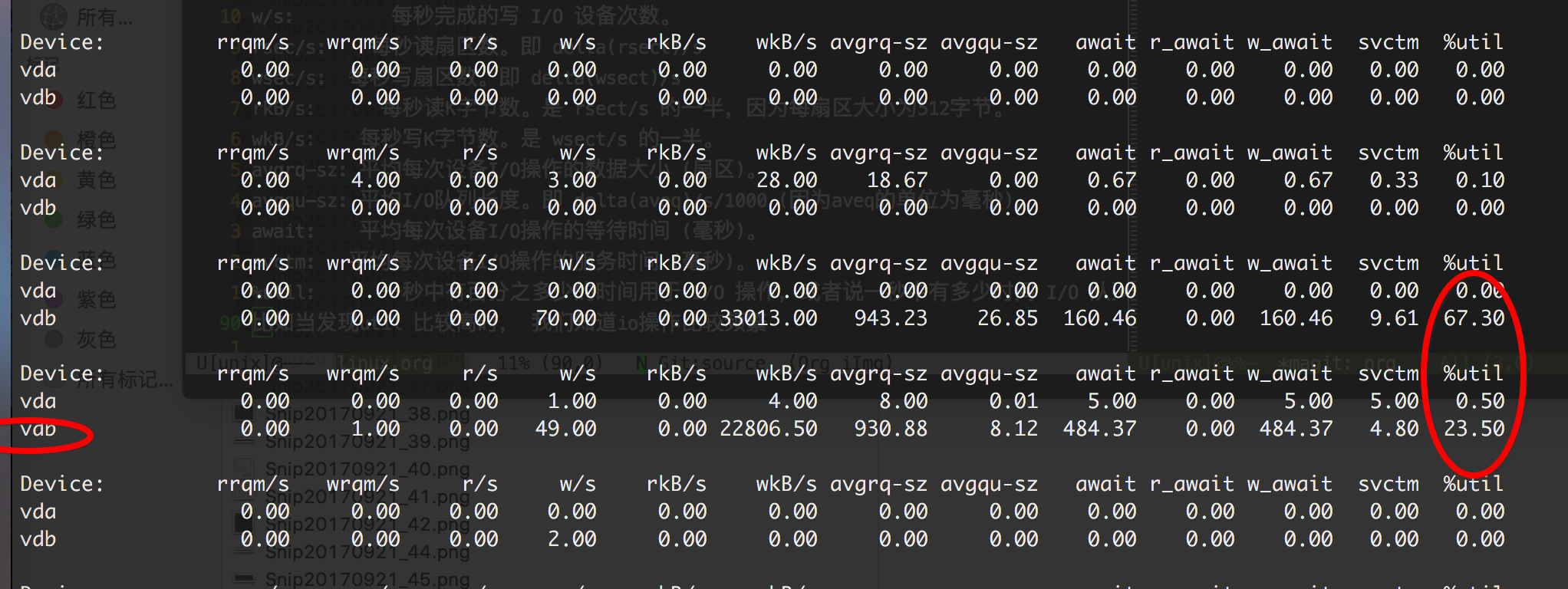
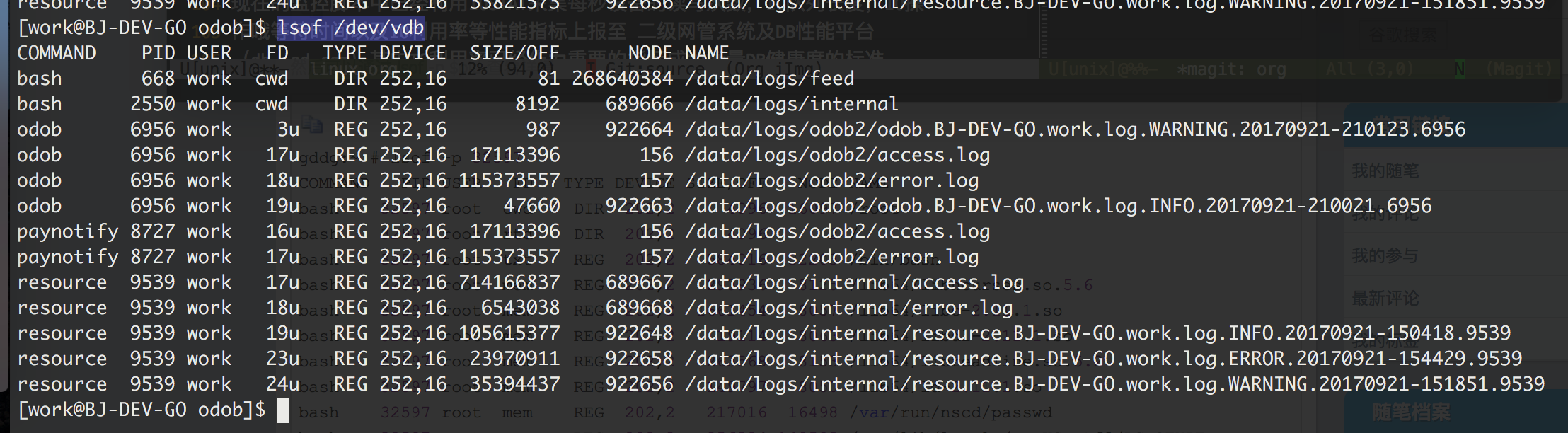
可以用lsof /dev/vdb 查看当前io主要针对的文件是什么,比如发现日志比较费io
注意:
输出结果的第一行是从系统启动到现在为止的这段时间的结果,接下去的每一行
是interval时间段内的结果。Kernel里有一组计数器用来跟踪这些值。所以我们
在取性能指标的时候要注意第一行指标的特殊性。
SUSE 10 和9 iostat 参数数量略有不同,suse 10 多出rkB/s ,wkB/两个参数,
不过意义不大,因为完全可以通过rsec/s,wsec/s计算得出。
现在的监控脚本中已经利用IOSTAT采集每秒设备的读写次数,IO队列长度,IO操
作哦等待时间以及IO利用率等性能指标上报至 二级网管系统及DB性能平台
(db.ied.com)其中IO利用率已经作为重要的指标成为衡量DB健康度的标准
VMSTAT 介绍
Vmstat(Virtual Memory Statistics)反映了进程的虚拟内存、虚拟内存、磁盘、trap和cpu的活动情况
基本语法:vmstat <options> interval count
option - 让你指定所需的信息类型,例如 paging -p , cache -c ,.interrupt
-i etc. 如果没有指定选项,将会显示进程、内存、页、磁盘、中断和cpu信息。
报告说明:
procs
- r:
运行的和等待(CPU时间片)运行的进程数,这个值也可以判断是否需要增加CPU(长期大于1)
- b:
处于不可中断状态的进程数,常见的情况是由IO引起的
- r:
- memory
- swpd: 切换到交换内存上的内存(默认以KB为单位)
如果 swpd 的值不为0,或者还比较大,比如超过100M了,但是 si, so 的值长期为 0,这种情况我们可以不用担心,不会影响系统性能。 - free: 空闲的物理内存
- buff: 作为buffer cache的内存,对块设备的读写进行缓冲
- cache: 作为page cache的内存, 文件系统的cache
如果 cache 的值大的时候,说明cache住的文件数多,如果频繁访问到的文件都能被cache住,那么磁盘的读IO bi 会非常小。
- swpd: 切换到交换内存上的内存(默认以KB为单位)
Swap
- si: 交换内存使用,由磁盘调入内存
- so: 交换内存使用,由内存调入磁盘
内存够用的时候,这2个值都是0,如果这2个值长期大于0时,系统性能会受到影响。磁盘IO和CPU资源都会被消耗。
常有人看到空闲内存(free)很少或接近于0时,就认为内存不够用了,实际上不能光看这一点的,还要结合si,so,如果free很少,但是si,so也很少(大多时候是0),那么不用担心,系统性能这时不会受到影响的。
- si: 交换内存使用,由磁盘调入内存
io
- bi: 从块设备读入的数据总量(读磁盘) (KB/s),
- bo: 写入到块设备的数据总理(写磁盘) (KB/s)
随机磁盘读写的时候,这2个 值越大(如超出1M),能看到CPU在IO等待的值也会越大
- bi: 从块设备读入的数据总量(读磁盘) (KB/s),
- system
- in: 每秒产生的中断次数
- cs: 每秒产生的上下文切换次数
上面这2个值越大,会看到由内核消耗的CPU时间会越多
- in: 每秒产生的中断次数
- cpu
- us: 用户进程消耗的CPU时间百分比
us 的值比较高时,说明用户进程消耗的CPU时间多,但是如果长期超过50% 的使用,那么我们就该考虑优化程序算法或者进行加速了 - sy: 内核进程消耗的CPU时间百分比
sy 的值高时,说明系统内核消耗的CPU资源多,这并不是良性的表现,我们应该检查原因。 - wa: IO等待消耗的CPU时间百分比
wa 的值高时,说明IO等待比较严重,这可能是由于磁盘大量作随机访问造成,也有可能是磁盘的带宽出现瓶颈(块操作)。 - id: CPU处在空闲状态时间百分比
- us: 用户进程消耗的CPU时间百分比
几个性能相关工具
dstat -tlcnimr –tcp -D xvdc

mpstat -P ALL 1
pidstat 1
iostat -xz 1
vmstat 1
free 命令详解
因为LINUX的内核机制,一般情况下不需要特意去释放已经使用的cache。这些cache起来的内容可以增加文件以及的读写速度。
先说下free命令怎么看内存
[root@yuyii proc]# free
total used free shared buffers cached
Mem: 515588 295452 220136 0 2060 64040
-/+ buffers/cache: 229352 286236
Swap: 682720 112 682608
其中第一行用全局角度描述系统使用的内存状况:
total——总物理内存
used——已使用内存,一般情况这个值会比较大,因为这个值包括了cache+应用程序使用的内存
free——完全未被使用的内存
shared——应用程序共享内存
buffers——缓存,主要用于目录方面,inode值等(ls大目录可看到这个值增加)
cached——缓存,用于已打开的文件
note:
total=used+free
used=buffers+cached (maybe add shared also)
第二行描述应用程序的内存使用:
前个值表示-buffers/cache——应用程序使用的内存大小,used减去缓存值
后个值表示+buffers/cache——所有可供应用程序使用的内存大小,free加上缓存值
note:
-buffers/cache=used-buffers-cached
+buffers/cache=free+buffers+cached
第三行表示swap的使用:
used——已使用
free——未使用
cache释放:
To free pagecache:
echo 1 > /proc/sys/vm/drop_caches
To free dentries and inodes:
echo 2 > /proc/sys/vm/drop_caches
To free pagecache, dentries and inodes:
echo 3 > /proc/sys/vm/drop_caches
说明,释放前最好sync一下,防止丢数据。
使某一目录下创建的所有文件目录的groupname 都是 当前用户所属的组
chmod g+s dir1
dir1以下的FILE和FOLDER组名都是当前用户所属的组
umask
umask就是指定“当前用户在建立文件或目录时候的属性默认值”
对于文件来说,这一数字的最大值分别是6。
目录则允许设置执行权限,这样针对目录来说,umask中各个数字最大可以到7。
我们只要记住u m a s k是从权限中“拿走”相应的位即可。
如:umask值为022,则默认目录权限为755,默认文件权限为644。
对于组权限,setfacl设置的权限只对主组(即useradd -g或usermod -g的组)
有效,对附加组(即useradd -G或usermod -aG的组)无效,即使文件的所有组已改为附加组。
setfacl
/etc/fstab 里加 acl 选项
/dev/sda2 / ext3 noatime,acl 0 1
mount -o remount /
给某个用户设置权限: setfacl -m u:joe:rx bobdir/ 给某个组设置权限: setfacl -m g:aclgp1:rx bobdir/ 取消某项权限 setfacl -x g:aclgp1 bobdir/
setfacl命令可以识别以下的规则格式。 [d[efault]:] [u[ser]:]uid [:perms] 指定用户的权限,文件所有者的权限(如果uid没有指定)。 [d[efault]:] g[roup]:gid [:perms] 指定群组的权限,文件所有群组的权限(如果gid未指定) [d[efault]:] m[ask][:] [:perms] 有效权限掩码 [d[efault]:] o[ther] [:perms]
setfacl -m d:g:groupA:rwx /path/to/perms The -m flag stands for "Modify" the existing ACL. The little d in front of g makes it a "Default" ACL, so that in future if any file/dir gets created under perms directory, groupA will have rwx permission on them too.
mbr and dd
MBR=主引导区记录。硬盘的0磁道的第一个扇区称为MBR,它的大小是512字节,而这个区域
可以分为三个部分。第一部分为pre-boot区(预启动区),占446字节;第二部分是
Partition table区(分区表),占64个字节,硬盘中分区有多少以及每一分区的大小都记
在其中。第三部分是magic number,占2个字节,固定为55AA。MBR是针对整个硬盘而言的,
而引导扇区是对单个分区而言的。每个分区的第一扇区就是引导扇区:像MBR一样,引导扇
区里包含了一些引导操作系统所需要的相关信息。如果引导扇区被破坏了是个非常严重的
问题,那就意味着这个分区不能被访问,安装在这个分区上的操作系统也不能被启动。所
以说修复引导是使得每一个分区都能被正确识别引导。
446+64+2=512 dd </dev/sda bs=512 count=1 >mbr512.img dd <mbr512.img bs=446 count=1 >/dev/sda dd <mbr512.img bs=1 count=64 skip=446 seek=446 >/dev/sda
nmap
tcpdump
sudo tcpdump port 80 # only 80 端口
sudo tcpdump -w filename port 80 # write to filename似乎 -w 参数不能太靠后
mac shutdown
. 10分钟后关机 sudo shutdown -h +10
. 晚上8点关机 sudo shutdown -h 20:00
linux下分辨率调整
http://blog.csdn.net/wangfaqiang/article/details/6289959
我的理解就是,长1440 宽900,深75 root@jf /home/jixiuf # cvt 1440 900 75 生成 Modeline这一行 # 1440x900 74.98 Hz (CVT 1.30MA) hsync: 70.64 kHz; pclk: 136.75 MHz Modeline "1440x900_75.00" 136.75 1440 1536 1688 1936 900 903 909 942 -hsync +vsync
然后,配成这面的样子,即可
Section "Monitor"
Identifier "Configured Monitor"
Modeline "1440x900_75.00" 136.75 1440 1536 1688 1936 900 903 909 942 -hsync +vsync
Option "PreferredMode" "1440x900_75.00"
EndSection
Section "Screen"
Identifier "Default Screen"
Monitor "Configured Monitor"
Device "Configured Video Device"
EndSection
Section "Device"
Identifier "Configured Video Device"
EndSection
通过ssh 连接远程机器上的mysql 等
通常的情况是远程 42.62.14.55 上有一个mysql ,兼听在3306端口上
但是防火墙阻止直接连3306端口
解决加法是 ssh 连上42.62.14.55 ,然后在ssh 访问mysql 3306端口,
此时防问
ssh -L 3307:localhost:3306 username@42.62.14.55 -N
这个时候在你的本机会开一个3307端口
然后 mysql -uroot -ppass -P3307 就可以连上这个mysql了
iptables 作端口转发
#!/bin/sh pro='tcp' NAT_Host='101.200.145.250' NAT_Port=3005 Dst_Host='101.200.145.250' Dst_Port=9001 iptables -t nat -A PREROUTING -m $pro -p $pro --dport $NAT_Port -j DNAT --to-destination $Dst_Host:$Dst_Port iptables -t nat -A POSTROUTING -m $pro -p $pro --dport $Dst_Port -d $Dst_Host -j SNAT --to-source $NAT_Host
以上脚本 当访问 NAT_Host:NAT_Port 时,请求会被转发到 Dst_Host:Dst_Port 端口
若不管用
sudo service iptables save 后
有可能需要把 /etc/sysconfig/iptables 内下面两行注释掉 重启iptables
#-A INPUT -j REJECT –reject-with icmp-host-prohibited //这两行最好是注释掉。在一般的白名单设置中,如果这两行不注释,也会造成iptables对端口的设置无效
#-A FORWARD -j REJECT –reject-with icmp-host-prohibited
iptables -L -n -a nat
ssh socat
我局域网ip 是192.168.1网段的
10.142.8.24 是位于另一网段的一台内网机器 ,
122.224.249.55 是一台有公网ip的机器,
10.142.8.24位于122.224.249.55后面
也就是说要想ssh连接到10.142.8.24需要途经 122.224.249.55
用到了socat这款软件做代理
使用如下命令,
本机ip: 192.168.1.127
防火墙 122.224.249.55 port 9991
内网机 10.142.8.24 ssh 端口开在36000上
sudo ssh -o ProxyCommand='socat - socks:122.224.249.55:%h:%p,socksport=9991' username@10.142.8.24 -p 36000
没加 sudo 之前一直给我提示Permission denied (keyboard-interactive),不知原因何
在,难道socat命令需要root权限
ssh tunnel
socks5 7070端口
ssh -p 2222 -D 0.0.0.0:7070 deployer@se.najaplus.com -N -4
ssh -p 2222 -D 7070 deployer@se.najaplus.com -N -4
-4 ipv4
ssh -L 3307:serverip:3306 root@serverip -N
则直接访问本机3307端口 相当于方法serverip的3306端口
ssh 反向tunnel 实现借助外网机访问内网机服务器
参考 https://my.oschina.net/abcfy2/blog/177094
在内网机上运行以下命令,则访问dev.najaplus.com 的3009端口相当于访问 内网机的22端口
autossh -M 5678 -NR 3009:localhost:22 deployer@dev.najaplus.com # 不太理理5678端口的作用在外网机上运行以下命令
实际上登录到内网相的22端口,即登录内网机的ssh,(内网机需要启动sshd) ssh -p 3009 jixiuf@localhost
另外在外网机上可以看到3009牌listen状态,且绑定在127.0.0.1,也就是说只能从本机对3009进行访问

同相的道理,假如内网机80端口有web服务
autossh -M 5679 -NR 3008:localhost:80 deployer@dev.najaplus.com
则在外网访问外网的3008端口 相当于访问内网机的80端口
结合nginx 代理3008端口即在任意地址访问外网的80端口来实现访问内网的服务
tsocks 配置
wget ,git 通过ssh tunnel 连网
tsocks wget http://googletest.googlecode.com/files/gtest-1.5.0.tar.bz2
tsocks git clone url
tsocks curl url
tsocks go get google.golang.org/grpc
tsocks 的安装
brew tap Anakros/homebrew-tsocks
brew install –HEAD tsocks
vim /usr/local/etc/tsocks.conf
server = 127.0.0.1
server_type = 5 #to use socks V5
server_port = 7070 #the port of your porxy%
类似工具
brew install proxychains-ng
/usr/local/etc/proxychains.conf
socks5 127.0.0.1 7070
adb shell
su
mount -o remount,rw / /
mount -o remount,rw /system
FAQ:提示没有权限如何处理?
cannot create hosts: read-only file system
出现以上红色问题,需要执行以下命令
adb kill-server 停止服务器
adb remount 重新挂载文件系统
adb reboot 重启手机
adb logcat 查看手机上的运行日志,此项可以用来查错
curl demo
curl https://api.sandbox.paypal.com/v1/oauth2/token -H "Accept: application/json"
-H "Accept-Language: en_US"
-u "AVNJj1L75UxFsQYwqBRk8s_5qc07ARsy-vznUCpnxLaP2pGqwzUXLFqaWANhBZjhGsrG83Ad7Xwtni1P:EBUuK3Gr7e5JFe7SxNAtvkas2NEvwoKwp-_UCMQwNymCCDHlJJ6OCtBwvWyDH03XXPfZgn49vcnBmHrC"
-d "grant_type=client_credentials"
-L follow redirect
time sync
cat /etc/ntp.conf|grep server会列出几个服务器
没有的话会http://www.pool.ntp.org/zone/cn%E6%89%BE%E7%A6%BB%E8%87%AA%E5%B7%B1%E6%9C%80%E8%BF%91%E7%9A%84server, 如
server 0.asia.pool.ntp.org
server 1.asia.pool.ntp.org
server 2.asia.pool.ntp.org
server 3.asia.pool.ntp.org
sudo yum install ntp 手动同步两次 sudo ntpdate -u 0.asia.pool.ntp.org sudo ntpdate -u 0.asia.pool.ntp.org sudo service ntpd start sudo chkconfig ntpd on #查看同步情况 watch ntpq -p
sed 一些用法
- 最常见的 sed 's/old/new/g' filename
如果想直接修改原文件
sed -i "" 's/2/3/g' a.txt # 或乾修改前将原文件备份为 a.txt.bak sed -i ".bak" 's/2/3/g' a.txt
提取匹配的某一部分 (这里最后用到了/p 估计是print 的意思)
比如文件有有一行内容如下,我想取出其中的数字部分
AC_PREREQ(2.65)
autoconf_min=`sed -n 's/^ *AC_PREREQ(\([0-9\.]*\)).*/\1/p' configure.ac` # 其中 \1 引用 \([0-9\.]*\) 匹配的部分
常用到从某文件中取版本号等
有条件的替换
sed -i '/SELINUX/s/enforcing/disabled/' /etc/selinux/config实现将 如果某行含有SELINUX 这个关键字,则把此行的 enforcing 替换成 disabled
实际实现了 将SELINUX=enforcing 换成SELINUX=disabled 这个功能
grep
grep -v 过滤 不匹配的行
grep -P 以perl正则来匹配(linux支持,mac不支持)
过滤@的行, 但是不过滤@case的行
grep -P "@(?!case)" #用到了零宽断言 (即@后不为case的)
grep [a,A]..[b,B]* file 在文件中查找a(或A)开头,第四个字母为b(或B)的所有单词
grep -E 'string1|string2' file 搜寻文件中或者存在string1或者存在string2的行
利用grep -c 来作instr()用
#!/bin/sh a="Hello i am pass"; if [ `echo $a | grep -c "pass" ` -gt 0 ] then echo "Success" else echo "Fail"; fi
find
# 修改时间在10天前的都删除 find . -maxdepth 1 -mtime +10 -exec rm -rf {} \; # 修改时间在10天之内的都删除 find . -maxdepth 1 -mtime -10 -exec rm -rf {} \;
“.”点号替代单个字符
这个用法真的非常非常有用,极力推荐。
grep [a,A]..[b,B]* file 在文件中查找a(或A)开头,第四个字母为b(或B)的所有单词
sed 's/^….//g' file 删除文件所有行的前4列
sed 's/^…..//g' file 删除文件所有行的前5列
shell for if example
# 过滤掉开头是#的注释行 for url in `cat $MODULE_FILE_NAME|grep -v "^[ \t]*#" ` ; do mod=`echo $url|sed 's|.*/||g'|awk -F '.git$' '{print $1}'` abs_mod_path=$WORD_DIR/$mod if [ -d $abs_mod_path ] && [ -d $abs_mod_path/.git ] ; then # 如果库已经存在 echo $abs_mod_path cd $abs_mod_path git checkout master git pull else cd $WORD_DIR git clone $url fi done
用python 格式化json
cat a.json|python -m json.tool
awk 怎么去除如果第一列相同,则只取一行?
例如:
aaaaaa,bbbbbb,ccccccc
sssssss,fffffffffff,wwwww
eeeeee,rrrrrrrrr,2222222
aaaaaa,qqqqqq,wwwwww
sssssss,wwwww,3333333
……………………………………
……………………………………
…………………………………….
…………………………………….
eeeeeee,tttttttttt,44444444
以逗号分隔,就是如果第一列是重复的,不管后边的列,只取一行,怎么取
awk -F, '!a[$1]++' urfile
! a[$1] ++
0为假, !0 为真
以第一列(逗号分隔)为索引的数组元素的值为0则输出,输出后数组元素值++, 后面的行$1相同时a[$1]的值就不为0了。
awk 替换
awk '{sub(/6.5.4/,"6.5.7");print}' globalrc awk '{sub(/package design/,"package cavedesign");print >"db_defs_design_select.go"}' ./data/output/db_defs_design_select.go
awk 在指定的行添加内容添加行
awk -v "n=line-number"\ -v 'line1=import "github.com/gogo/protobuf/gogoproto/gogo.proto"; '\ -v 'line2=option (gogoproto.marshaler_all) = true;'\ -v 'line3=option (gogoproto.sizer_all) = true;'\ -v 'line4=option (gogoproto.unmarshaler_all) = true;'\ '(NR==2) { print line1;print line2;print line3;print line4 } 1;' pf.proto
压测用工具
ab -n 1000000 -c 1000 -p /tmp/a -T application/json -H "X-UID: 1000000013" http://diary.dev.igetget.com/diary/v1/data/list
-n 总请求数
-c 并发数
其中/tmp/a 为post 的内容
siege -c 1000 -b -q -r 1000000 -H "X-Uid: 1000100366" -H "X-Av: 3.0.9" -H "X-D: aaa" -f choicesnow.txt
-c 并发
-r repetition 次数,重复次数
-b 表示benchmark
-q quiet
-f 后是文件, 里面内容每行表示一个http的请求,形如
baidu.com POST column_id=1&id=2
google.com POST column_id=1&id=2
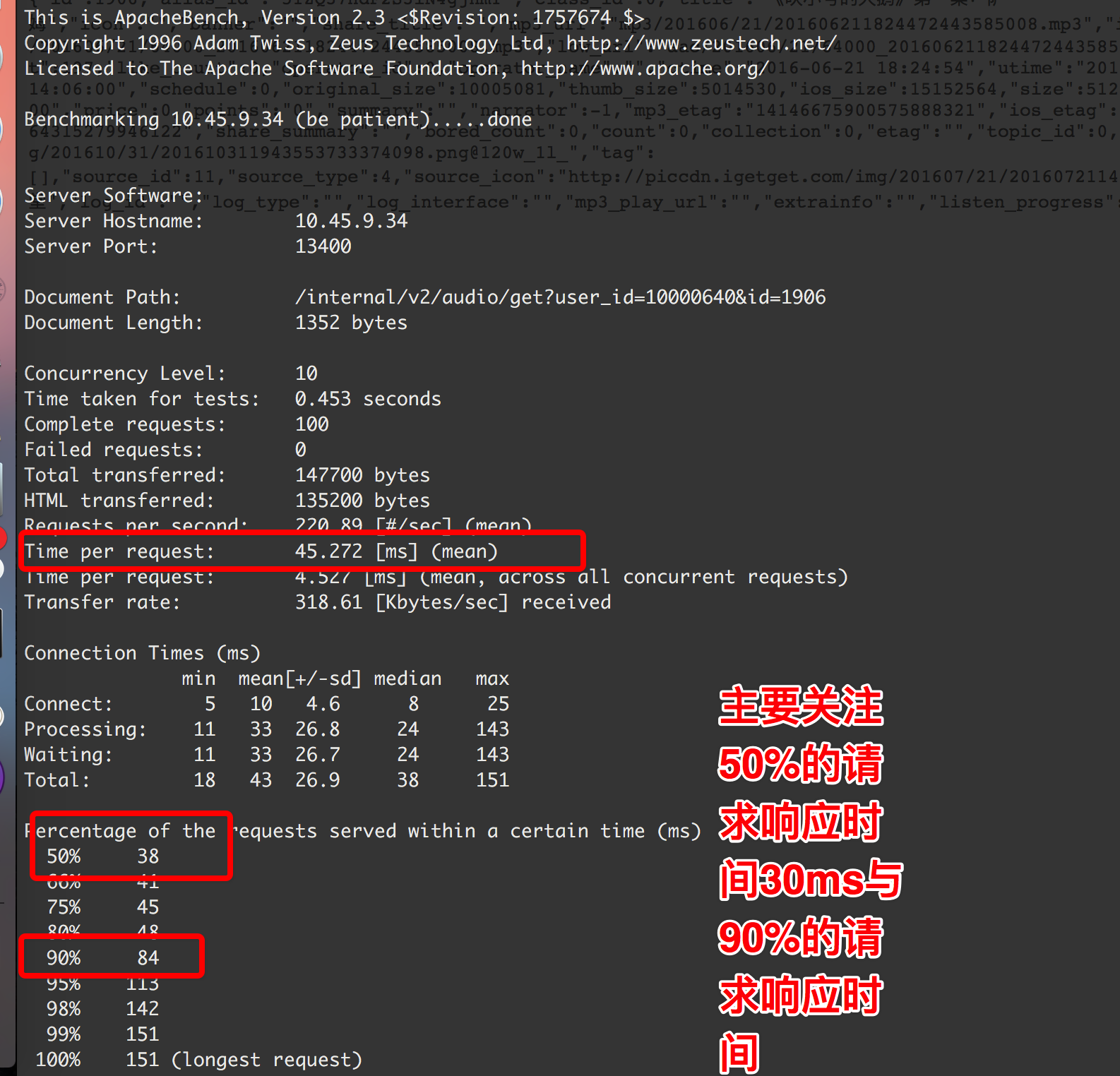
ab http压测
ab -c 100 -n 100 http://url 并发100 ,共1000个请求
一个请求 响应时间20ms左右为佳,随着并发量会略有增加 但100ms是个阀值
超过100ms 虽然也可能正常,但该考虑优化, 比如加缓存等
tcpcopy 线上数据导入测度服进行压测
使用charles在移动设备上捕获https数据包
主要利用中间人欺骗来实现
如何应对三高
高可用
隔离 降级
低延迟
静态化
缓存
性能优化 (硬件\os\)
扩展性
隔离
线程进程隔离 (不同业务逻辑 使用不同优先级的线程池等,各业务不会相互影响)
读写分离(db,queue写消峰)
动静数据分开(一张表 多变与不变者分)
热点隔离 冷热数据分开
资源隔离(根据业务物理上拆库拆缓存)
限流(基本都是拿到令牌的才允许进一步访问,没拿到令牌的,前端就挡回,拿到的后端服务要验证令牌)比如小米限量抢购
要前端分配令牌的 可以做成无状态的,可以无限水平扩展,
令牌桶算法
漏桶算法
应用层限流
限流总并发,连接,请求
限流资源数
限流时间窗口内请求数
是否需要平滑(1秒一个, 还是1min60个)
分布式限流
接入层限流
nginx +lua
ngx_http_limit_conn_modules限制并发连接数 (配置)
ngx_http_limit_req_modeles (配置)
openresty lua-resty-limit-traffic
apigateway
降级预案
主动降级(业务相关 开关进行控制) 被动降级
降级开关
读降级 写降级(异地多活,数据中心出问题,不允许写,但是可读) 如数据库
ssh 避免输入密码的办法
#!/usr/bin/expect spawn ssh hello@ip expect "*password:" send "yourpasswordhere" expect "*#" interact